


Aplicaciones Big Data en detección fraudes
La proliferación de la tecnología moderna ha producido técnicas de fraude más sofisticadas. Pero los avances tecnológicos también han permitido enfoques más inteligentes para detectar los fraudes. En un mundo en el que las transacciones y los documentos se registran digitalmente, hay evidencia disponible para ayudar a los investigadores en la batalla contra los esquemas fraudulentos. La pregunta más difícil es "¿cómo encontrar fácilmente y rápidamente esa evidencia?".
Una herramienta de detección de fraudes y riesgos puede ahorrar una gran cantidad de recursos. Cualquier empresa que deba asumir riesgos o pagar liquidaciones por siniestros asociados a pólizas de seguros se puede ver beneficiada. Por ejemplo, empresas que sufren estafas reiteradas tales como compañías de tarjetas de crédito o compañias de telefonia celular o fija. Los comportamientos descubiertos de esta forma, pueden sugerir cambios en los procesos de negocio, para reducir los riesgos. La identificación de situaciones anómalas, como por ejemplo, el cambio de perfil de consumo de un cliente, puede impedir pérdidas millonarias. El ahorro producido paga cualquier proyecto de implementación de técnicas de detección de riesgos insertadas en sistemas de información.
Estas empresas tiene grandes cantidades de datos, donde se almacenan tanto aquellas transacciones "normales" como las clasificadas como riesgosas. Entre estas transacciones se encuentran escondidos patrones. Identificando estos patrones se pueden detectar aquellos casos de riesgo, para informarlos a quienes deben tomar las acciones que correspondan.
Metodología
Nuestra empresa puede apoyarlo en cualquiera de los pasos que propone la metodología KDD (Knowledge Discovery in Databases), estándar actual para el descubrimiento de conocimiento en grandes bases de datos (patrones). En la figura que se muestra a continuación se describe el proceso.

Los servicios que ofrece NEURONET pueden apoyar en cualquiera de las fases de la metodología. Por ejemplo, dentro de los 3 primeros pasos, podemos realizar:
- Selección de atributos de importancia (utilizando algoritmos y/o estudios con expertos).
- Reducción de dimensionalidad y determinación de características.
- Procesos de limpieza de datos.
- Generación de atributos de importancia no almacenados de forma explicita (por ejemplo promedio de gastos médicos por persona).
- Transformación de datos nominales a binarios.
En la etapa de minería podemos apoyar en la generación de modelos utilizando tecnologías de última generación como son las máquinas de soporte de vectores o redes neuronales. Ambas han demostrado ser exitosas en tareas de detección de fraudes en variadas aplicaciones como seguros médicos o tarjetas de crédito.
NEURONET puede apoyar en la transformación del conocimiento adquirido durante el proceso en una herramienta que apoye los procesos de su empresa. Esta va a ser capaz de detectar fraudes utilizando los patrones descubiertos y avisar a quien sea necesario cuando se determine la ocurrencia de uno.
Tecnologías disponibles
En el caso particular de las técnicas de detección de fraudes, puede verse como un problema de clasificación. Cada nueva transacción debe catalogarse como fraudulenta o normal. Otra opción, es modelarlo como un problema de detección de anomalías. En este segundo caso, se debe determinar si una nueva transacción es diferente a aquellas consideradas normales (según datos históricos). La opción más conveniente dependerá de la disponibilidad de datos, de la estructura de estos y de los objetivos específicos de la organización.
Generalmente al plantear la detección de fraudes como un problema de clasificación se presentan dificultades con la distribución de datos, ya que el porcentaje de fraudes es mucho menor que el de transacciones normales. Esta dificultad puede ser solucionada de varias maneras, encontrándose entre las más utilizadas el entrenamiento ponderado o la selección ponderada de registros.
Redes Neuronales Artificiales
Las redes neuronales artificiales, RNA son modelos matemáticos que pueden ser entrenados para aprender relaciones no lineales entre un conjunto de datos de entrada y un conjunto de datos de salida . En medicina la aplicación más común y exitosa de estos modelos, es la clasificación de patrones con el propósito de apoyar al médico en el diagnóstico y tratamiento del paciente. También se ha utilizado con éxito en la detección de fraudes médicos.

Support Vector Machine
En machine learning, Support Vector Machine (SVM) son modelos de aprendizaje supervisados con algoritmos de aprendizaje que analizan los datos utilizados para la clasificación y el análisis de regresión. Dado un conjunto de ejemplos de entrenamiento, cada uno marcado como pertenecientes a una u otra de las dos categorías, un algoritmo de entrenamiento de SVM construye un modelo que asigna nuevos ejemplos a una categoría u otra, convirtiéndolo en un clasificador lineal binario no probabilístico . Un modelo SVM es una representación de los ejemplos como puntos en el espacio, mapeados de modo que los ejemplos de las categorías separadas se dividan por una brecha clara que sea lo más amplia posible. Nuevos ejemplos se mapean en ese mismo espacio y se predice que pertenecen a una categoría basada en qué lado de la brecha caen.
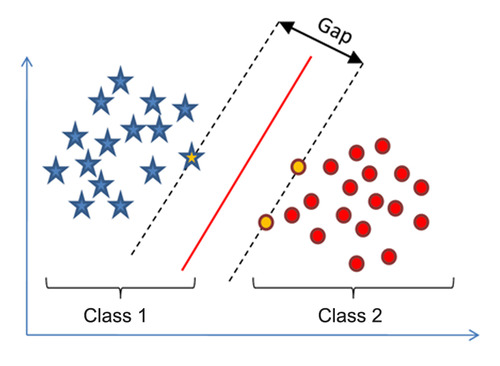
Support vector machine es una tecnología que soluciona alguno de los problemas que tienen las redes neuronales y que es la tendencia actual en la minería de datos. La gran deficiencia de las redes neuronales es que sus métodos de entrenamiento no aseguran la obtención de un óptimo global. Este problema no lo tienen las maquinas de soporte de vectores.
Las máquinas de soporte de vectores funcionan llevando cada dato a un espacio de mayor dimensión, mediante una transformación o kernel. En este nuevo espacio se busca el mejor híper plano capaz de dividir las clases en esta nueva representación. Una sólida base matemática les permite asegurar que en un espacio lo suficientemente grande las clases serán divisibles fácilmente y que el híper plano encontrado es el mejor posible. En la siguiente imagen se ilustra este concepto, donde datos en dos dimensiones son llevados a tres y luego un híper plano es encontrado.

Consideraciones en el uso de Modelos para detección de fraudes
Una dificultad que tiene el modelar la detección de fraudes como un problema de clasificación es que probablemente el sistema tendrá un buen funcionamiento con fraudes conocidos, encontrados antes del entrenamiento, pero no podrá detectar correctamente nuevos tipos. Por esta razón, en los primeros meses de uso mostrará excelentes resultados pero puede empeorar a medida que avanza el tiempo.
Como se mencionó anteriormente el problema también puede verse como una detección de anomalías. En este caso se intenta caracterizar de la mejor forma posible aquellas transacciones "normales", para luego detectar si una nueva es extraña. De esta forma, para preparar el modelo solo se utilizan transacciones que no han sido catalogadas como fraude. La gran ventaja de esta visión es que es posible detectar fraudes que nunca han sido vistos anteriormente. A diferencia de lo anterior donde solo se identificaran aquellos usados en el entrenamiento.
Para la generación de un modelo como este, se recomienda la utilización de máquinas de soporte de vectores de una clase. Estas presentan una modificación a la estructura normal de este tipo de modelos que permite enfrentar datos de entrenamiento donde todos los registros pertenecen a la misma clase. Esta tecnología ya ha sido utilizada en la detección de fraudes con excelentes resultados.

Consultoría DataWarehouse
Las organizaciones manejan y almacenan altos de volúmenes de datos diarios. Extraer información de estos datos es una tarea cada vez más compleja y clave para negocios competitivos. Una solución de la industria de TI a esta problemática es lo que conocemos como DataWarehouse... Ver más
Inteligencia de Negocios
La competitividad y el futuro de una organización dependen de una buena toma de decisiones. La inteligencia de negocios, o business intelligence, es una herramienta moderna para el descubrimiento de información valiosa a partir de datos almacenados en distintas fuentes... Ver más

Oracle Business Intelligence
Oracle Business Intelligence Enterprise Edition (OBIEE), es la más completa plataforma de reportería, análisis, OLAP, dashboards interactivos y scorecards. Entrega una completa experiencia al usuario final que incluye colaboración, visualización, alertas y más... Ver más

Servicios de Big Data
Los datos se han vuelto omnipresentes con el crecimiento exponencial de las nuevas tecnologías de oferta de datos digitales. Manejar este creciente volumen de datos es el último desafío para las empresas que quieren aprovechar el valor de estos datos para su negocio... Ver más