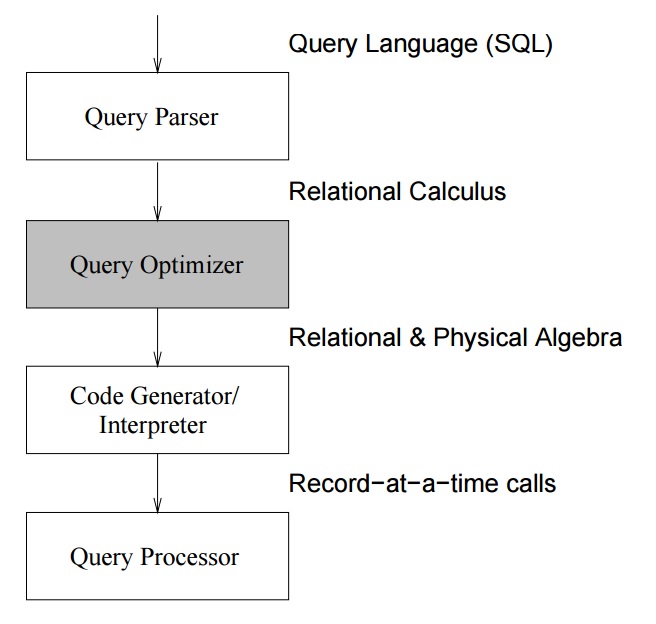
El optimizador DBMS
Una de las componentes de un DBMS más poderosas (y a la vez menos conocida por parte de los desarrolladores) es el OPTIMIZADOR DBMS.
Imagínese Ud, de pie, delante de un exquisito buffet lleno de numerosas delicatessen. Su objetivo es probar todos estos manjares frente a ud, pero tiene que decidir en qué orden. ¿Qué intercambio de gustos maximizará el placer global de su paladar? Difícil tarea.
Aunque subjetivo y mucho menos placentero que el problema anterior, este es el tipo de planteamientos que los optimizadores de consultas están llamados a resolver. Dada una consulta, hay muchos planes que son equivalentes en términos de salida y que el DBMS puede aplicar para procesar la consulta y producir su resultado. Todos los planes de ejecución son equivalentes en cuanto a su resultado final, pero varían en su costo, es decir, la cantidad de tiempo que necesitan para ejecutarlo. ¿Cuál es el plan que necesita el menor tiempo posible?
El OPTIMIZADOR es una componente que recibe un SQL de parte de un usuario y como resultado debe entregar el plan de ejecución (métodos de acceso y secuencia de pasos de como se resuelve la consulta) que posea el menor «costo». Este resultado del OPTIMIZADOR DBMS tiene la forma de un árbol invertido. Un SQL puede tener muchos árboles con resultados equivalentes, pero con costos de ejecución que pueden ser dramáticamente diferentes.
Para ello los RDBMS definen funciones de costo internas que dependen del I/O, la CPU y el tráfico de datos que fluya, siendo el I/O la variable de mayor peso en esta función de costo.
Por ejemplo, consideremos el siguiente esquema de base de datos
emp(emp#, enombre, edad, sal, dpto#)
dept(dpto#, dnombre, piso, presupuesto, director, cta#)
cuenta(cta#, tipo, saldo, banco#)
banco(banco#, bnombre, direccion)
Y consideremos la siguiente consulta SQL (muy simple):
SELECT emp#, enombre, dnombre
FROM emp, dept
WHERE emp.dpto#=dept.dpto# AND sal > 100.000;
Asumamos las siguiente características de la base de datos:
| Descripcion Parámetro | Valor Parámetro |
| Numero de paginas tabla emp.emp# de tuplas tabla emp.emp# de tuplas tabla emp con sal > 100.000Numero de paginas table deptNumero de tuplas tabla dept | 20.000100.0001010100 |
| Indices de emp Indices de dept | Indice clusterizado Btree sobre emp.sal, 3 niveles de profundidad.Indice de hash sobre dept.dno (promedio de largo de bucket 1,2 paginas) |
| Numero de paginas de buffer | 3 |
| Costo de un acceso a disco | 20 ms |
Consideremos los siguientes planes:
P1: A través del árbol B + encontrar todas las tuplas de emp que satisfacen la selección sobre emp.sal. Para cada uno, utilizar el índice hash para encontrar las tuplas correspondientes de dept. (Nested loops, utilizando el índice clusterizado de ambas relaciones.)
P2: Para cada página de departamento, realizar full scan de toda la relación emp. Si una tupla de emp coincide con en el atributo dno de una tupla de dept y satisface la selección sobre emp.sal, entonces el par tupla emp-dept aparece en el resultado. (nested loops a nivel de página, sin usar ningún índice.)
P3: Para cada tupla de dept, realizar full scan de la relación emp y almacenar todos los pares de tuplas emp-dept. Después haga una búsqueda de este conjunto de pares y, para cada uno, comprobar si tiene los mismos valores en los dos atributos de dno y satisface la selección sobre emp.sal. (Formación a nivel de tupla del producto cartesiano, con la posterior exploración para probar el join y la selección.)
Por simplicidad, si se evalúa únicamente el costo de I/O de estos 3 planes se tienen los siguientes costos de ejecución:
P1 tiene un costo de 0,32 segundos
P2 tiene un costo de un poco más de una hora
P3 tiene un costo mayor a un dia completo
Es evidente que el optimizador debiera elegir el plan 1 como plan de ejecución de la consulta.
Referencias:
Query Optimization Yannis E. Ioannidis, Computer Sciences, Department, University of Wisconsin
SQL Server query optimizer architecture